
Today, we have accomplished to sequence genomes from living beings. Well, not all, but at least we have a quite comprehensive sequence for human and mice.
So, does that mean that we know how life works? How living things were encoded by ACGTs?
Well, not really. Sequencing the genome is just the start. What's next is to understand what it means. And, that is what Functional Genomics is all about.
Right now, we are taking new tools to understand what the genome does. We now have high throughput technologies that can generate whole lots of data and allows us to ask genome scale questions. In other terms, we can screen what happens, what changes, in the genome in different conditions. We can ask, "Can we find a gene that's important for process X?"
Truly, discovery in functional genomics is limited and driven by technology development. It drives and limits our ability to ask question in mass scale. And it's what limiting our knowledge right now. So, in this post, I will talk to you about several Functional Genomic Technologies that are available right now, how to use it, and how to handle the data generated.
Microarray Technology (Gene Expression Array) - The Foundation for Functional Genomics
To start with, functional genomic technologies allow us to do large scale measurement of transcription. Suppose you want to identify different genes expressed by human cancer line in response to a drug treatment. So, what you need to do is: (1) treat the cancer cell lines with drug and compare it with untreated one, (2) purify the cells, (3) extract the RNA and make its cDNA/RNA, so, in each tubes we will have ten thousands of RNA molecules. Then, we want to know how many of each different RNA is expressed in comparison with control.
What we can do is using Microarray technology to do transcriptional profiling. DNA microarray uses collection (library) of DNA spotted in a solid surface, where each spot contains different specific DNA sequence called probes. This probes can be short section of genes or other part of the genome.
First, we couple the RNA samples (target) with labels, which could be a radioactive labels (in the old times) or a fluorescent tags/dye. Then, we hybridize the target with probes. Because of the complementary base pairing, the sample will hybridize with its correct probe pair, and we then wash off the non-specific bindings. Then, using a high resolution image analysis, we can capture the intensity strength of the hybridized probes, and tried to finish the puzzle: (1) which probes expressed differently, and (2) intensity changes: which goes up and which goes down. Then, we can analyse the result summary and statistics. This way, we can make a comparative statement on what is going on in the treated and untreated.
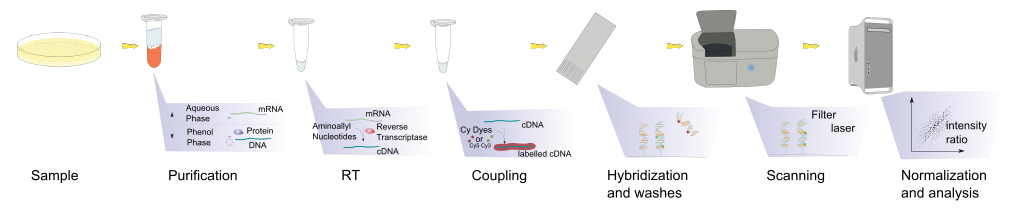 |
| Overview of DNA microarray process (wikipedia)
Spotted vs Oligonucleotide Microarrays
The difference between spotted and oligonucleotide microarray is the probe used in analysis. In spotted array, the probes are oligonucleotides, cDNA, or small fragment of PCR product that correspond to mRNA. Oligonucleotide microarrays uses short sequences which are designed to match known or predicted open reading frames. So, basically, the spotted microarray are more specific and usually used in-house, where it can be modified for each experiments. So, it is better to use spotted microarray if you already know which genes are predicted to change or targeted. Meanwhile, the oligonucleotide can give whole genome results and usually used to screen what is happening in the genome. Two-Channel vs One-Channel Detection There are different ways to label and see the differences between samples: two-channel or one-channel. In two channel detection, each of the two sample were labelled using different fluorophore dyes (usually its Cy3 and Cy5), mixed together, and hybridized in a single microarray. This way, relative intensities of each fluorophore can be used to analyze up-regulated and down-regulated genes. In single channel detection, you don't mix it. So it's one microarray per sample. But, this only indicate relative abundance when comparing with different samples. Why? Because each samples will encounter protocol or batch specific bias during amplification, labelling, and hybridization. So, looks like its obvious to choose the two channel detection right? Actually it's not. Why? Its because if you want to use multiple comparisons, then you will need more combination for two channel detection while you only need one array per sample using the one channel. And microarrays are still helluva expensive. In conclusion, it is not feasible. In fact, one of the most used microarray platform today is the Affymetrix Gene Chip (Hope to make the tutorial too), which is the one-channel detection platform. There are other advantages in using one-channel detection: (1) because each array is exposed to one sample, aberrant sample would not affect raw data of other sample, and it is more flexible to compare with other experiment as long batch effect is accounted for. A Rapidly Changing Field: Why You Should Learn Some R Programming Both strategy would have complication in processing the raw data, but the statistical approach for each platform have been rapidly developed in the recent years. The field was rapidly developing which makes it a bit hard to make a good graphical interface software (it will be outdated a soon as new things published). Rather, people will just upload their code scripts (usually in R language) through open source platform. That is why, basic R language and maybe UNIX command will be necessary to keep updated with this technology. In the coming tutorial, we will use Bioconductor and R to analyze example of Affymetrix data. The Gene Expression Omnibus (GEO) Right now, lots of data has been generated, and they are stored in the gene expression omnibus. Have a look :) Key Microarray Technologies Here are some key applicaiton of microarray technology, and we will discuss it more in the next part of this post.
High-Throughput Sequencing (HTS): A Close Relative Nucleic-acid based arrays are quite mature, but in the coming years, low-cost high-throughput sequencing technologies will be used as alternative (or replace?) the technique. Some early technologies were Serial Analysis of Gene Expression (SAGE) shown below which basically generates cDNA from RNA population, tags them, and concatenate them for sequencing. Then, we can count the number of cDNA tags and map them to genome. But, we will see some of the newest technology in the next part. 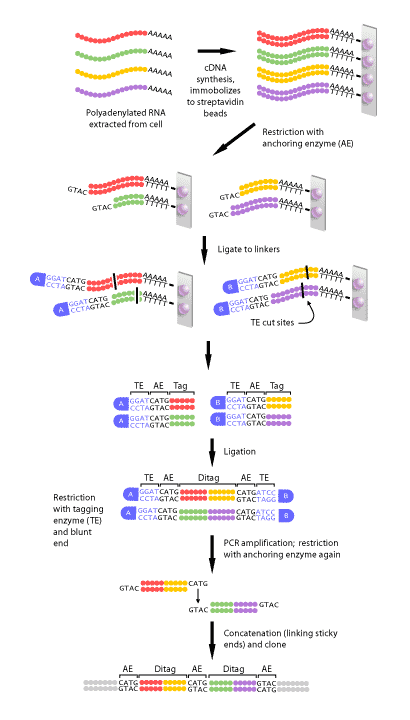 Closing for the First Part Really, functional genomic allows us to ask genome scale questions, but to make it tell you something biologically relevant, you cannot just relies on statistics alone, it is a combination between measurement and annotation. Next: Microarray Technologies! |






0 comments :
Post a Comment